Yesterday, Microsoft released the source code for MS-DOS 4.0... an action which I have encouraged Microsoft to take for many years (including when I worked at Microsoft).
And, while this source code release is most definitely a win for the preservation of computer history, there are some rather ridiculous issues with it.
Most notably:
- The source doesn't actually fully compile. It is not usable in its current state.
- The source code has been modified by Microsoft -- even after the publication this week -- reducing the historical value of the code.
- Also Microsoft claims to have lost some source code.
Yeah. You read that first bullet point right. It does not compile. I'll walk you through the details (including a step-by-step guide for how you can fail to compile MS-DOS 4.0 yourself).
But, first, a little backstory.
The MS-DOS 4.0 Story (The Short, Short Version)
MS-DOS 4.0, released back in 1986, was a bit of an oddity. It was a multitasking version of DOS (similar in that way to Wendin-DOS). And, importantly, it was not a direct continuation of the existing MS-DOS line -- in fact "MS-DOS 4.0" was released between versions "3.1" and "3.3" (almost exactly coinciding with the "3.2" release).
Fun Side Note: There are multiple multitasking variants of DOS (or ways to multitask in DOS). Most of which were not built or supplied by Microsoft. In case you didn't know that... now you do.
This Multitasking MS-DOS 4.0 was not commercially successful -- to put it mildly -- and that line of "Multitasking MS-DOS" was quickly abandoned.
Luckily -- or not luckily, depending on how you look at it -- IBM co-developed a completely different version of "MS-DOS 4.0" that had almost nothing to do with the multitasking version Microsoft created. This IBM-made version, a continuation of MS-DOS 3.x, continued to be single-tasking. But, oh-boy, was it buggy. Legendarily buggy.
Ultimately, when it was obvious that the Multitasking "MS-DOS 4.0" was a dead-end, Microsoft took IBM's totally unrelated "MS-DOS 4.0" and released it also as "MS-DOS 4.0". (Two different Operating Systems, same name and same version number. Because that's not at all confusing.) Then -- quickly -- re-worked a bunch of it -- releasing that as "MS-DOS 4.01".
That single-tasking version ("4.01") went on to have some success -- though it is widely regarded as one of the buggier releases of MS-DOS.
The MS-DOS 4.0 Source Release
Two totally different things named "MS-DOS 4.0". So what, exactly, is Microsoft releasing the source code for?
Well. There are two parts.
- A version of the source code for the IBM-developed, not Multitasking version of MS-DOS 4.0.
- An earlier Beta build of the Multitasking version of MS-DOS 4.0 (from 1984, long before it was even called "4.0"). No source code is available (other than for BIOS related utilities for OEMs), but there are some scanned documentation, which is nice from a historical viewpoint.

Both are available via GitHub. And everything is released under the MIT license.
Which means that, yes, if you can get that single-tasking 4.0 code to build... you can, in theory, fork these releases and continue developing them. (Though you'll need to change the name, as Microsoft still holds the trademarks.)
This work was announced in a joint blog post by Jeff Wilcox (Head of Open Source Programs Office) and Scott Hanselman (Vice President of Developer Community) at Microsoft.
Fun Side Note #2: That Vice President, Scott Hanselman, is the same Microsoft executive who has previously encouraged people to commit crimes against people based on their skin color and gender. Telling people to be ready to "go to jail" for those crimes. While that bit of information has absolutely nothing to do with the MS-DOS 4.0 source code release... it's nice to have background on the people in the story.
What code, exactly, did we get?
This release, from Microsoft, is a valuable and interesting one. It contains a great deal of historically significant information -- and I am absolutely filled to the brim with nerdy joy as I go through it.
Unfortunately... it does not include code for the multitasking version of "4.0".
From the announcement:
"Jeff Wilcox and OSPO went to the Microsoft Archives, and while they were unable to find the full source code for MT-DOS, they did find MS DOS 4.00, which we’re releasing today, alongside these additional beta binaries, PDFs of the documentation, and disk images. We will continue to explore the archives and may update this release if more is discovered."
As a former Microsoft employee... this is... strange. And, quite honestly, not at all believable.
During my time working at Microsoft, I knew of backed up copies of source code for darned near everything -- including almost every version of MS-DOS from 3.3 onward (that I, personally, saw).
Yet they were unable to find code for the Multitasking MS-DOS 4.0? Knowing, intimately, how the various groups within Microsoft handled backing up source code and binaries for releases... this statement from Microsoft makes me highly skeptical.
Unless Microsoft completely forgot how to backup source code in the last few years, I'm going to call this claim utterly bogus.
Is it Actually MS-DOS 4.0?
Just to make everything far more confusing than it already is... this may not actually be MS-DOS 4.0. It might be MS-DOS 4.01... or PC-DOS 4.01... or some strange combination.
Take a look at SETENV.BAT in the source code release and you will find the following line:
echo setting up system to build the MS-DOS 4.01 SOURCE BAK...
What files I have been able to build appear to exactly match the MS-DOS 4.0 (not 4.01) release images. But, being as some of this source code release is mangled beyond use, unfortunately we can't really be sure that everything matches the actual 4.0 release. It might be an interim build between 4.0 and 4.01.
Oh! That's right.
Did I mention that this source code release of MS-DOS 4.0 doesn't successfully build?
The Code Does Not Compile
Allow me to repeat myself:
The code that has been supplied contains significant problems which will prohibit it from compiling a complete, working version of MS-DOS 4.0.
I attempted build under multiple environments (including on a released version of MS-DOS 4.01, MS-DOS 5, PC-DOS, and under DOSBox) -- and dug through the errors until I was confident of the issues (and, importantly, was confident that we weren't simply looking at an obvious case of user error).
Note: If you want to skip the "How To Build It" portion, simply scroll down to the "BOOM! ERROR!" section below.
Want to unsuccessfully build MS-DOS 4.0 yourself? Here are some super easy to follow steps.
- Download the contents of the MS-DOS 4.0 GitHub repository.
- Install DOSBox. (Seriously, this works just as well in DOSBox as it does anywhere else.)
- Within DOSBox run the following command: "MOUNT D PATH" (replace "PATH" with the path to that folder you downloaded in step 1).
If you did everything correctly, you will now -- within DOSBox -- have a D:\ drive with a directory named "SRC" in it.
The BAT and make files which build MS-DOS 4.0 expect all of the files to be in D:\SRC. So replicating that environment will make it so you don't need to tweak any files at all.
Now we actually do the build.
- Change to the D:\SRC directory. "D:" then "CD SRC".
- Now run "SETENV.BAT". This will setup the paths and whatnot for the build environment.
- Then simply run "NMAKE". That will kick off the build for everything.
Easy, right?
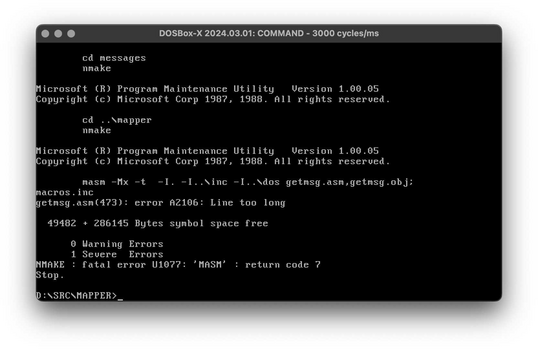
BOOM! ERROR!
At this point you will quickly see that several files compile cleanly. Until you get to GETMSG.ASM and, later, USA.INF. Both of these files are mangled. I was able to force GETMSG.ASM to compile by commenting out some lines... but USA.INF is completely hosed.
I don't see how whoever uploaded this source could have possibly done a successful compile prior to releasing it.
Seriously. Hosed, I say! Hosed!
It's not all bad news, luckily. The majority of the code does appear to be here -- and most of it builds without any catastrophic errors. With some work (a replaced file here, some re-written code there) I am confident a variant on this MS-DOS 4.0 release will be able to be built... unfortunately, because of changes needed to make it compile, it won't be a historically perfect replica of the system.
Not without Microsoft figuring out what they did wrong and re-releasing the source code. Which, considering how rarely Microsoft releases source code for these historical pieces of software... I won't be holding my breath.
Fun Side Note #3: After Microsoft announced the source code release of MS-DOS 4.0, a huge number of articles have popped up on a number of Tech News sites. Tech Journalist after Tech Journalist praising the release. Yet not one of them has reported that the code does not actually compile. Which means that none of them even tried to verify the claims from Microsoft. Not. One. Except for The Lunduke Journal, of course. I'll let you draw your own conclusion about what that means.
The historical record has been compromised... a little.
It doesn't build. That's a problem.
Also, it's kind of hard to be 100% sure what this specific release even is (is it 4.0... is it 4.01... is it from IBM or MS? An interim build? It looks mostly like 4.0... but there's some weird bits that could use clarification.).
But what makes this even worse... is that not only has some of the code been mangled and corrupted... but some of the code comments were actively modified in the few hours after the source code was publicly posted!
Thus further destroying the historical value of this source code. Which, to put it mildly, kinda sucks.
Brain-damaged Tim Patterson
But, as luck would have it, that source code change... is really, really amusing. And pretty minor.

A modified comment. "Brain-damaged Tim Patterson" becomes "Brain-damaged TP".
It's a simple change -- obscuring an insult of Tim Patterson (the original creator of Quick & Dirty DOS)... replacing his full name with his initials. But, if this is a historical record, this change should not occur.
Here's a fun question: Who, exactly, made this change? Microsoft is not accepting any changes to this source code repository from the outside world. So, whoever made the change has the blessing of Microsoft.
Well, hold on to your butts!
This change was made by GitHub user "mzbik", with the simple comment "MZ is back!".
Ok. Great. But who the heck is "MZ"?
None other than the legendary Mark Zbikowski. One of the early Microsoft employees (joining in 1981) -- and the programmer who took over the MS-DOS project (from Tim Patterson) starting with version 2.0... and leading DOS through version 4.0.

Clearly Mark -- who usurped Tim as the Dev Lead / Manager of MS-DOS -- did not want that little "Brain-damaged" insult of Tim to be part of the historical record.
Or, perhaps, he really wanted to call attention to it by making the change.
Either way, we now can be somewhat sure that Mark Zbikowski, himself, wrote that comment way back in the 1980s. And, even more fascinating, Mark remembered that comment -- from the '80s -- so clearly that he knew to quickly go and change it -- almost immediately -- once the source was made public. (I barely remember source code comments I made last week, let alone almost 40 years ago... this really stuck with him!)
And that level of irreverent whimsy -- one historically significant programmer insulting another historically significant programmer... in source code comments -- makes me smile.
Ok, sure. That change isn't a huge deal. In fact, I'm now glad it happened as it drew my attention to it.
But what else has been changed? What else will be changed? It's worth asking. This is for the preservation of history, after all.
Lots and Lots of Questions
In fact, this release raises a lot of questions.
- Why was building of this source code not tested prior to release?
- What process caused these source code files to be mangled?
- What all was changed from the original source archive?
- Why has Microsoft only released source code for the 3 least popular versions of MS-DOS (1.25, 2.0, & 4.0)? Microsoft does not profit from versions 3.3, 5.0, or 6.x (far more popular and/or useful releases). Why are those being held back?
- Microsoft loves to tell people how much they love Open Source... yet they have released source code for only a very small number of products (far less than 1% of their total software releases). Even ancient software, unsuported for decades, remains closed source. Why?
- The last release of MS-DOS source code (versions 1.25 and 2.0) occurred 10 years ago (2014). Why has it taken 10 years to release source code that Microsoft hasn't used since the 1980s? Will the next release of source code be 10 years from now... in 2034?
- And, shoot, why has not one other Tech News publication actually tried to compile this code... or notice the changes being made... or look into the details at all?
I don't mean to sound like a Negative Nancy, here. This release is, without a doubt, incredibly interesting and important.
And Microsoft is under no obligation to release the source code for these pieces of software. No obligation whatsoever. If they wanted to keep it all locked away in their vault, that's entirely their call.
That said, Microsoft's near constant declarations of their "love for Open Source" -- including their ownership of GitHub -- would suggest to me that they would be eager to release the source for 30 and 40 year old software that they haven't earned a penny on in decades.
If they truly loved the idea of "Open Source"... they would do it. In a heartbeat. But they don't. Which tells me a lot about their actual views on "Open Source".
Some things never change...
When I worked at Microsoft -- in the late 1990s and early 2000s -- I pushed, regularly, to release code, binaries, and documentation of historicaly significant Microsoft software. The old stuff that nobody used anymore, but which should be preserved and studied for posterity.
Back in those days, I got a lot of push-back. To put it mildly.
Microsoft management was extremely hesitant to release code -- and even free binaries -- of these historic products. And, honestly, it looks like that situation has barely improved since then. Shoot. What they do release doesn't even compile.
Just the same: I applaud Microsoft for releasing this MS-DOS 4.0 code! Truly, I do!
Now... release some more! Preferably without mangling the code this time.
And don't give me any of that "we can't find the code for our most famous products" malarkey. The Lunduke Journal knows better.