The United States Court of Appeals (Second Circuit) just issued a ruling against the Internet Archive (Archive.org) -- rejecting their appeal, and upholding a previous ruling against them in the Hachette vs Internet Archive legal battle.
Make no mistake: This is very bad news for both the Internet Archive, Archive.org users, as well as other archival projects.

Hachette v. Internet Archive: The Short, Short Version
To make sure everyone is up to speed, here is the short, short version of this legal battle.
For many years, the Internet Archive has been creating digital copies of physical books (by scanning them) -- then allowing people to "borrow" those digital versions from Archive.org (in theory limiting the total digital books being "lent out" to the count of the physical books in the Archive's possession).
They never obtained permissions from the authors or publishers to do any of this.
In 2020, during the Covid lockdowns, the Internet Archive launched the "National Emergency Library" -- where they removed that "1 physical book : 1 digital book lent out" restriction. Meaning anybody on the Internet could obtain digital scans of physical books... and the Archive could "Lend Out" an unlimited number of digital copies based on a single physical copy.
Again. No permission was obtained from the writers or publishers.
Thus -- to the surprise of absolutely nobody -- the "Hachette v. Internet Archive" legal battle began.
And... The Internet Archive lost. The judge ruled in favor of the publishers (including Hachette, Wiley, Penguin Random House, & HarperCollins).
Naturally, Internet Archive appealed that ruling. But, boy-howdy, was their appeal a strange one which was destined to fail.
The Strange Appeal of The Internet Archive
On April 19th of 2024, the Internet Archive filed their final brief in their attempt to appeal this ruling against them.
In that ruling, one of the Internet Archive's core arguments was that it cost the Internet Archive a lot of money to make so many digital copies of books without permission... so, therefore, the Internet Archive should be allowed to do it.
That is neither a joke nor an exaggeration. It sounds weird, because it is weird.
The Internet Archive truly attempted to make the case that spending a lot of money committing a crime... should make that crime legal. (Could you imagine the mafia making that case? Wild.)
You can read the full analysis, by The Lunduke Journal, of the appeal (including the appeal itself) for yourself for more details.
The reality is... there was never any chance that the Internet Archive's attempted appeal was going to be successful. Their defensive arguments were highly illogical (bordering on flights of fancy), and brought nothing new or noteworthy to the case. This was all painfully obvious.
The Lost Appeal
On Wednesday, September 4th, 2024, the opinion was handed down from the United States Court of Appeals.
While the full ruling is roughly 64 pages long, this single paragraph -- from the second page -- summarizes things quite well:
"This appeal presents the following question: Is it “fair use” for a nonprofit organization to scan copyright-protected print books in their entirety, and distribute those digital copies online, in full, for free, subject to a one-to-one owned-to-loaned ratio between its print copies and the digital copies it makes available at any given time, all without authorization from the copyright-holding publishers or authors? Applying the relevant provisions of the Copyright Act as well as binding Supreme Court and Second Circuit precedent, we conclude the answer is no. We therefore AFFIRM."
To call out the truly important parts:
"Question: Is it 'fair use' ... to scan copyright-protected print books in their entirety, and distribute those digital copies online, in full, for free ... all without authorization from the copyright-holding publishers or authors? ... we conclude the answer is no."
You can read the entire 64 page ruling for yourself. Heck. You can even read it on Archive.org. But that line, right there, sums it all up.
Naturally, the Internet Archive has issued a statement. Albeit... a short one.
"We are disappointed in today’s opinion about the Internet Archive’s digital lending of books that are available electronically elsewhere. We are reviewing the court’s opinion and will continue to defend the rights of libraries to own, lend, and preserve books."
What Happens Now?
The Internet Archive gets sued by some of the biggest book publishers... and loses.
The Internet Archive appeals... and loses.
What happens next? Well. Unfortunately -- for both the Internet Archive, and its users -- the future looks rather bleak.
First and foremost: Has the Internet Archive made, and distributed, digital copies of work you own? This ruling will certainly not hurt your case should you decide to take legal action against Archive.org.
And -- holy smokes -- the amount of copyrighted material on Archive.org is absolutely massive.
The Archive.org software repository alone contains millions of items. With a very large number of them being copyrighted material, posted there without permission of the copyright owner.
Simply going by the numbers, here's how much material is available on Archive.org (roughly):
- 832 Billion archived webpages.
- 38 Million printed materials (magazines, books, etc.).
- 2.6 Million pieces of software
- 11.6 Million videos files.
- 15 Million audio files.
- 4.7 Million images.
How many of those items do you think are there without permission (or possibly even knowledge) of the owners or creators?
Every single one now has an increasingly strong case when looking at potential legal action.
And it's about to get even worse for the Internet Archive.
UMG Recordings v. Internet Archive
That's right, the book publishers weren't the only ones taking legal action against Archive.org.
Universal Music Group and Sony have an ongoing lawsuit against the Internet Archive -- regarding the distribution of 2,749 audio recordings (with potential damages upwards of $412 Million USD).
Seriously.
"Plaintiffs bring this suit to address Defendants’ massive ongoing violation of Plaintiffs’ rights in protected pre-1972 sound recordings. As part of what Defendants have dubbed the “Great 78 Project,” Internet Archive, Blood, and GBLP have willfully reproduced thousands of Plaintiffs’ protected sound recordings without authorization by copying physical records into digital files. Internet Archive then willfully uploaded, distributed, and digitally transmitted those illegally copied sound recordings millions of times from Internet Archive’s website."
Sound familiar? Digital copies. No permission from the artists or publishers. Free downloads for everyone.
Naturally, the Internet Archive attempted to have this suit dismissed... but their attempt was denied in May of 2024. (Because if there's one constant in life... it's that the Internet Archive always loses in court.) That case is going forward.

What happens if the Internet Archive loses this UMG / Sony case? What happens if they are ordered to pay $412 Million in damages?
To put it simply: Archive.org doesn't have that kind of money. They bring in roughly $20 Million (give or take) per year. That type of legal liability would absolutely destroy the Internet Archive.
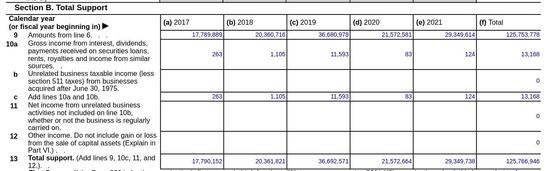
And, here's the thing, the Internet Archive is almost assuredly going to lose that lawsuit as well.
Regardless of what you, I, or anyone else thinks of the Internet Archive -- and, make no mistake, I use that service several times a week (and love it) -- the law here is incredibly clear and well tested.
The Internet Archive runs one of the largest (if not the largest) website of pirated and stolen digital material on the planet. Sure, it may also provide extremely valuable (and often, very legal) services as well.. but that doesn't make those crimes go away.
With each legal defeat, the Internet Archive grows increasingly vulnerable to additional attacks.
Simply being logical about it... it seems highly likely that we'll see additional suits brought against the Internet Archive in the months ahead. Books, music, TV shows, software... Archive.org contains a massive mountain of copyrighted material in all areas. These are suits which the Internet Archive would be almost certain to lose.
With this reality looming, how long until Archive.org will be forced to shut down entirely? That day is likely not far off... and a sad day it will be.
The Archive Had to Know This Was Coming
The truly sad part? The leadership of the Internet Archive had to know exactly what they were doing.
Every step of the way, it was obvious that they were going to lock horns with publishers (and lose).
Heck, I told them. Repeatedly.
But, even if The Lunduke Journal hadn't pointed this out... it was a brutally obvious certainty to anyone even mildly familiar with copyright law and the workings of Archive.org.
Which means: The Internet Archive knowingly put their entire service at risk (including the Wayback Machine, the massive archive or pre-copyright audio recordings, etc.) because they wanted to publish copyrighted material against the wishes of the authors or publishers.
Despite this, they continue to push a public perception campaign where they pretend that publishers and authors are burning their own books. When the reality is... the books are still available a wide variety of ways. Archive.org simply got in trouble for copying and distributing them without permission.
Something I find truly fascinating about all of this, is that The Lunduke Journal will -- as usual -- get yelled at (rather extensively) for this article. For simply pointing out the current reality of copyright law and how the Internet Archive has, knowingly, violated it.
People love Archive.org. Heck, I love Archive.org.
And people are allowing their love for that website to convince them that anyone being critical of it... must, necessarily, be bad and evil. An enemy.
But it is not The Lunduke Journal who is putting The Internet Archive in danger of being shut down.
Neither is it Sony, Hachette, Random House, or HarperCollins who are putting The Internet Archive in danger.
No, sir.
The only one putting The Internet Archive in danger... is The Internet Archive.