Kilobytes (KB). Megabytes (MB). Gigabytes (GB).
We use these storage measurements every single, gosh-darned day. And most of us feel like we know exactly what they mean. But do we really?
Do we really — truly — know what a “Byte” is… and its origin? I mean… who came up with the term “Byte”, anyway?
Let’s take a moment to look over the history of the term. If, for no other reason, than to feel smarter than most other nerds.
What is a “Byte”?
If you ask Mr. Google, a Byte is exactly 8 Bits.
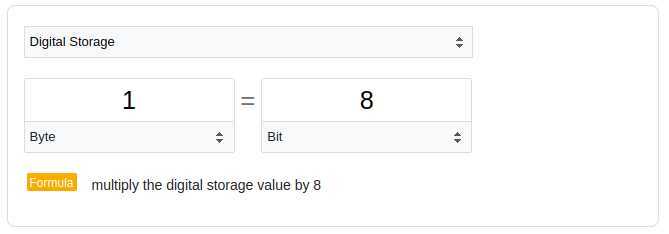
Ok. Great. 8 Bits = 1 Byte.
So what is a Bit?
That part is simple.
A Bit is the smallest unit of information for a digital computer. A Bit can have two possible values… 0 or 1. It is a boolean. A binary.
Many people believe “Bit” is short for “Bite”. You find this in many computer history books. This little tidbit has been repeated so often, many believe it. However, like many such oft-repeated anecdotes in computing… it’s hogwash.
In fact, “Bit” is an acronym for “Binary Information Digit”. Squish that phrase together and you get “Bit”.
Fun factoids about the origin of the “Bit”
The first usage of the word “bit”, when talking about a type of data in reference to computing, was by Vannevar Bush. He published an articled entitled “Instrumental Analysis” in the October, 1936 issue of “American Mathematical Society”. In it he used the phrase “bits of information” when talking about punch cards.
However…
“Bit” was commonly used in Middle English to refer to “a mouthful” or a “morsel” of food. (This is the origin of why many believe “Bit” is short for “Bite”… even though it isn’t.) As such, Vannevar Bush may not have actually been thinking about a “Bit” as a “Binary digit”… instead he may simply have thought “this is a morsel of data”. Also worth noting… Bush never actually defines what a “bit” is. Making it likely that he was simply using the word “bit” in the Middle English way.
The first — distinctly verifiable — usage of “Bit” in this way is by John Tukey. From “A Mathematical Theory of Communication” written by C. E. Shannon in 1949:
“The choice of a logarithmic base corresponds to the choice of a unit for measuring information. If the base 2 is used the resulting units may be called binary digits, or more briefly bits, a word suggested by J. W. Tukey. A device with two stable positions, such as a relay or a flip-flop circuit, can store one bit of information.”
There you have it. More information about the origin of the term “bit” than you ever wanted to know.
You’re welcome.
Ok. Great.
So, in short, a Bit is a 0 or 1. And a Byte is a group of 8 Bits. Easy.
Not so fast there, sport!
While the Byte being 8 Bits is commonly accepted today… that was not always the case. Not by a long shot!
In fact, there are two competing stories for who created the term “Byte”… and neither of them were referring to a set of 8 Bits!
Seriously!
Werner Buchholz’s 6 Bits
The most often cited creator of the term “Byte” is Werner Buchholz — who used the term, in 1956, to refer to a grouping of 6 Bits when working on the IBM Stretch Super computer.

A “6 Bit” Byte was common in those days. In fact, Braille was a 6 Bit encoding of characters for the blind. And many of the early computers (from IBM and others) used 6 Bit groupings to encode character data.
6 Bits -- not 8 Bits -- per Byte.
However (you knew there had to be a “however”)…
Louis G. Dooley’s N Bits
Around that same time (1956 or so), Louis Dooley first used the word “Byte” to refer to an undefined grouping of “Bits”. But, typically, used as “4 Bits”.
That's right. Not 8 Bits. Not 6 Bits. But 4 Bits.
Dooley published the following letter in BYTE magazine:
“I would like to get the following on record: The word byte was coined around 1956 to 1957 at MIT Lincoln Laboratories within a project called SAGE (the North American Air Defense System), which was jointly developed by Rand, Lincoln Labs, and IBM. In that era, computer memory structure was already defined in terms of word size. A word consisted of x number of bits; a bit represented a binary notational position in a word. Operations typically operated on all the bits in the full word.
We coined the word byte to refer to a logical set of bits less than a full word size. At that time, it was not defined specifically as x bits but typically referred to as a set of 4 bits, as that was the size of most of our coded data items. Shortly afterward, I went on to other responsibilities that removed me from SAGE. After having spent many years in Asia, I returned to the U.S. and was bemused to find out that the word byte was being used in the new microcomputer technology to refer to the basic addressable memory unit.
Louis G. Dooley
Ocala, FL”
So… what the heck is a “Byte”?!
That’s right. We now have two very, very different definitions for the word “Byte”. Both creations of the word happened independently… and at almost the exact same moment in time.
- “The Buchholz Byte” - A grouping of 6 Bits.
- “The Dooley Byte” - A grouping of an undefined number of bits, less than a full word size. Often used to describe 4 Bits.
You’ll note that neither of these definitions — from the men who created the term — have the number “8” in them.
The shift towards 8 Bits per Byte started to happen in the 1970s… with the development and gaining popularity of 8-Bit processors, such as the legendary Intel 8008.

Interestingly, some of those early 8-Bit CPU’s had specific functions for handling 4-Bit chunks of data. Because, up until that point, 4 and 6-Bit “Bytes” were incredibly common (including in the predecessor to the Intel 8008… the 4-Bit Intel 4004).
Fun Factoid: Nowadays a 4-Bit group is called a “Nibble”. Which is adorable.
For quite some time the term “octet” or “octad” was used to denote 8 Bit groups. At some point along the way, most people phased that out as well… simply referring to all “groups of bits” as a “Byte”. Though you will still find “octet” used here and there, especially when talking about various network protocols.
All of which means…
Dooley invented the modern “Byte”… not Buchholz
While many writers, enthusiasts, and computer historians are quick to say that Werner Buchholz coined the term “Byte”… they are obviously mistaken.
Besides the fact that it’s hard to discern who (Dooley or Buchholz) actually used the term first… the Buchholz definition is no longer used at all in modern computing.
The Buchholz definition is specific. 6 Bits. Which modern computing has determined is not the amount of Bits in a modern Byte.
The Dooley definition, on the other hand, allows for wiggle room. Which means that an 8 Bit “Byte” would fit the Dooley definition. But not the Buchholz.
The facts are clear: Louis G. Dooley created the word “Byte”. At least as it has been used for the last 40+ years.
But Buchholz — an absolute legend in the computing world — gets one heck of an Honorable Mention trophy.