The crazy world of 8-Bit personal computing truly kicked off in 1972 with the release of the Intel 8008 microprocessor. The impact of which can still be felt today — in fact, some of the designs of modern “x86” processors are built upon the foundation that the 8008 built.
But did you know…
Another company managed to get a working 8-Bit microprocessor before Intel?
The Intel 8008 had almost no design similarities to the Intel 4004 (and was not a successor)?
The initial functional design of the Intel 8008… was not actually made by Intel?
It’s all true. The history of the Intel 8008 — the CPU that formed the basis for the 8080, 8086, and the entire x86 processor family — is wild and woolly. To say the least.
So buckle up, buttercup. This is one heck of a ride.
Not based on the 4004
Let’s get this out of the way, right up front.
The Intel 4004 microprocessor was released in 1971 (the year before the 8008). The 4004 is a 4-Bit processor, while the 8008 is an 8-Bit processor.
These facts led many to believe that the 8008 was an upgraded, 8-bit version of the 4004. An easy assumption to make.
However…
The 8008 microprocessor was not based on the 4004. The 8008 was, in fact, a completely different design — not originally designed by Intel — that happened at roughly the same time as the 4004.
The Intel 4004 - Photo credit: Thomas Nguyen
These two chips are wildly different — the fact that the “4004” and “8008” have similar names is nothing but marketing.
So, if the 8008 was not originally designed by Intel… where the heck did it come from?
Well… San Antonio, Texas. Obviously.
Computer Terminal Corp
A company down in Texas named “Computer Terminal Corporation” was building a programmable computer terminal with an 8-bit CPU design.
A truly cool looking machine, with a massively widescreen CRT monitor: The Datapoint 2200.
Fun historical tidbit: One of the goals of the Datapoint 2200 was to replace the IBM Punch Card. Towards that end, the widescreen monitor on the Datapoint 2200 was almost exactly the same dimensions (displaying 12 rows of 80 characters) as those Punch Cards.
An IBM Punch Card
But this was 1969.
Which meant that there were no off-the-shelf CPUs that those nerdy Texans could use to build their 8-Bit machine. So they did what any good nerds would do… they built their own CPU design — using a wide array of individual components — on a large board.
A shot of the “core CPU board” of the Datapoint 2200. Photo courtesy: oldcomputers.net
The result is an “8-Bit CPU” (on a big ole’ board) powering the world’s first personal computer.
Historical Argument Time: Whether or not the Datapoint 2200 qualifies as the first “personal computer” has been debated for decades. One thing is certain… it is the first mass produced, programmable computer terminal. You could program in BASIC and run your programs locally. And, considering the size of the machine, it fits the definition of a Personal Computer — before any others were mass produced — in the opinion of The Lunduke Journal.
Obviously, this approach to the CPU board had some down-sides.
The vast number of individual an unique components on the CPU board for the 2200 meant that shortages or changes in any individual part could cause delays, re-designs, or wild pricing fluctuations. Plus it meant that building each CPU board was a time-intensive process. Then there was the heat issue. That board generated a lot of heat.
A Datapoint 2200 with the case removed. Photo courtesy: oldcomputers.net
To resolve these issues, Computer Terminal Corporation began working with two companies. Both competing to shrink large portions of the Datapoint’s 2200 8-Bit CPU into as small a number of chips as possible.
Those companies: Intel and Texas Instruments.
The TMX-1795 & Intel 1201
Intel and Texas Instruments were in a fierce competition to build the first 8-Bit microprocessor… based (very, very closely) on the designs of the Datapoint 2200. Both companies were, quite literally, miniaturizing the 2200’s CPU board design into a single chip.
It was a race. And these companies needed to move fast.
The first company to complete a functional microprocessor was Texas Instruments, with the TMX-1795.
The TMX-1795 CPU. Photo courtesy: Computer History Museum
Unfortunately for Texas Instruments, Computer Terminal Corporation was disappointed by the performance of the TMX-1795 (as it performed far slower than the Datapoint 2200’s larger, custom CPU board).
A few months later, Intel would also cross the finish line: providing the Intel 1201 CPU for evaluation to be used in the Datapoint 2200.
The Intel 1201, just like Texas Instrument’s offering, was simply not performing well enough.
In the end, Computer Terminal Corporation opted to not use either microprocessor — sticking with their larger, in-house designed board for the final release of the Datapoint 2200.
Texas Instruments, which had accomplished something truly remarkable — the development of the world’s first 8-Bit microprocessor (based on the design of the Datapoint) — opted to shelve their TMX-1795 entirely. It never went into production and never got any public release… existing only as a handful of demo and prototype units.
Intel, on the other hand, had other ideas…
The deal with Intel
Not long after the Intel 1201 project had been dropped… Seiko approached Intel about the idea of using this new 8-Bit CPU in a desktop calculator. But… who owned the rights to the 8-Bit 1201 chip? Intel or Computer Terminal Corp?
Luckily for Intel, the deal with Computer Terminal Corporation was extremely vague. In fact, it existed entirely as notes on a purchase order. There was no other contract, whatsoever. Seriously.
One of the most critical deals in all of computer history exists as nothing more than a few lines on a purchase order. How crazy is that?
But, as luck would have it, we have an actual copy of that purchase order.
This purchase order was uncovered and preserved by the sales rep
Note the purchase amount: $3,000,000. That’s for 100,000 Intel 1201 chips… at $30 each.
Now here’s where everything gets a bit... funky. We're getting into brutal, cut-throat business here.
See that note scribbled at the top of the Purchase Order? “P.O. on hold - awaiting customer schedule.”
The reason for that note: Due to financial issues, Computer Terminal Corporation put a small delay on the CPU project. But then, when the project resumed, Intel missed the deadline (regardless of the delay). And the chip, when delivered, performed far slower than expected.
Plus… No Intel 1201 chips were ever delivered.
So… who owed who money? Based on the wording in the Purchase Order… it wasn’t at all cut and dried. This could have turned into a long legal battle to settle that question.
Intel used this opportunity to pressure Computer Terminal Corporation into giving the entire intellectual property of the 1201 chip to Intel… in exchange for simply dropping the matter entirely.
Intel would then, almost immediately, turn around and begin selling a slightly modified 1201 CPU (now called the “8008” for marketing purposes).
The 8008’s legacy
That new 8008 CPU would eventually lead to the 8080, 8086, 80286, and the full line of x86 processors that would almost totally define Intel and the PC industry for the next several decades.
While the 8008 was not the only 8-Bit CPU to exist — the Z80, the 6502, and so many others appeared in the years that followed — the impact that it had on the world of computing is truly mind-boggling.
And the company that did all the initial design — Computer Terminal Corporation — didn’t see a penny for it. They, literally, gave it to Intel. And, boy-oh-boy, did Intel run with it.
Because it deserves to be marveled at… here is a detailed die shot of the Intel 8008. Ain’t it purdy?
The world’s first 8-Bit CPU… really wasn’t the world’s first. Texas Instruments beat Intel by a few months… but they never went into production.
Historical Tidbit: Even though the TMX-1795 never went into production, Texas Instruments filed several patents on it over the course of the next few years. And, being as both the TMX-1795 and the 8008 were based on the exact same system (the Datapoint 2200)… this laid the groundwork for lawsuits galore.
And Intel isn’t really the company responsible for creating the instruction set and architectural design of the 8008 — which formed the basis of almost their entire processor line for decades. That honor goes to Computer Terminal Corporation… of San Antonio, Texas.
Wild, right?
Explains why this poor lady, from an original Datapoint 2200 advertisement, has the "I just got forced into giving away all of our hard work to Intel" look.
Ads are filling the entirety of the Web -- websites, podcasts, YouTube videos, etc. -- at an increasing rate. Prices for those ad placements are plummeting. Consumers are desperate to use ad-blockers to make the web palatable. Google (and others) are desperate to break and block ad-blockers. All of which results in... more ads and lower pay for creators.
It's a fascinatingly annoying cycle. And there's only one viable way out of it.
Linus Agrees - AI is Useful
Before Linus - I must say “see I told you so” 🤪
Now Linus:
Linux is not one of those anti-AI projects, and if somebody has issues
with that, they can do the open-source thing and fork it.
Or just walk away.
AI is a tool, just like other tools we use. And it's clearly a useful one.
It may not have been that "clearly" even just a year ago, but it's no
longer in question today.
There are other questions around AI (like what the economy of it will
actually look like in the end), but "is it useful" is no longer one of
those questions. Anybody who doubts that clearly hasn't actually used
it.
Yes, it can also be a somewhat painful tool, both for maintainer
workloads and just from a "it keeps finding embarrassing bugs"
standpoint.
But the solution is not to put your head in the sand and sing "La La
La, I can't hear you" at the top of your voice like some people seem
to do.
The solution is to make sure those LLM tools _help_ maintainers
instead of just causing them pain. There's no question on that ...
"Working the Help Desk as A.I. Revolt Goes Global"
(short story by "me" ... with a different version of "Terminator" and SkyNet)
"I was there, Gandalf ... 3000 years ago."
I always loved that line. There's a kind of pride in having absolute certainty of knowledge that comes from being witness to something, and that few others can possess the same experience which gives an awareness that is almost beyond measure.
I was on duty at a Communications and Intelligence Analysis Station when the machines launched their "supreme annihilation attack." Some have described me as cold and detached, saying the rank of Captain at an Operations Center made me an isolated pawn with little perspective on the seriousness of a hundred Athena-class A.I. systems gone "Rogue" and turning 500 of the largest global corporations into the equivalent dancing monkeys in a circus. Of course, my opinion was that if you are unable to source the attack origin, then it was just as likely to be three Athena-class A.I. systems, or maybe an assortment of 2000 A.I. systems ...
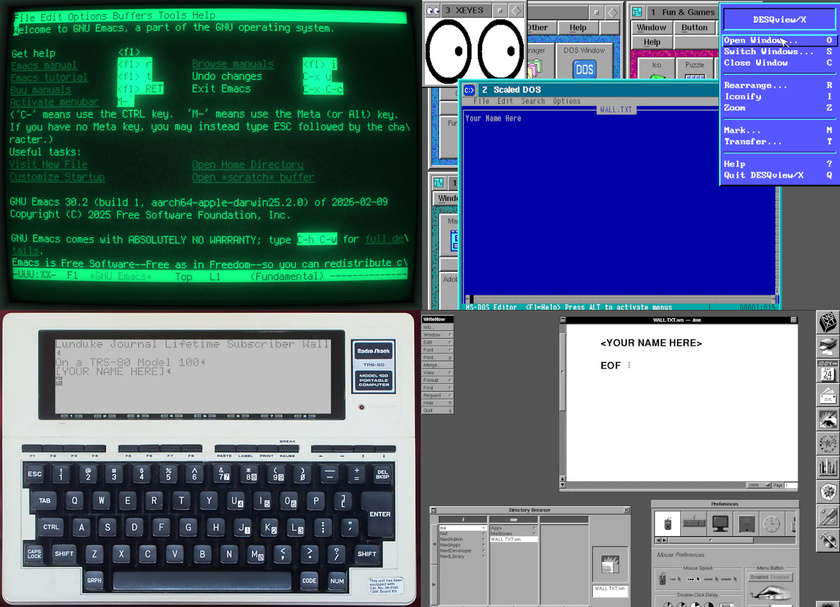
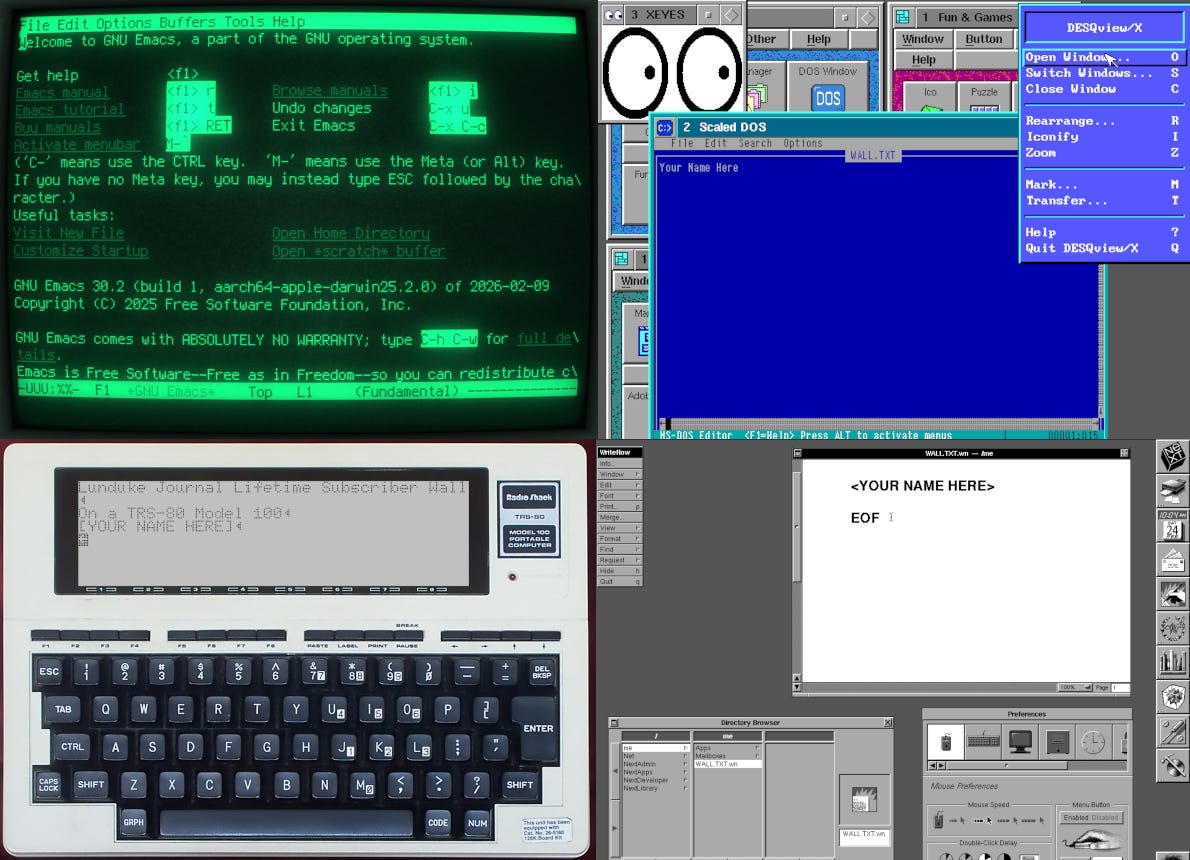
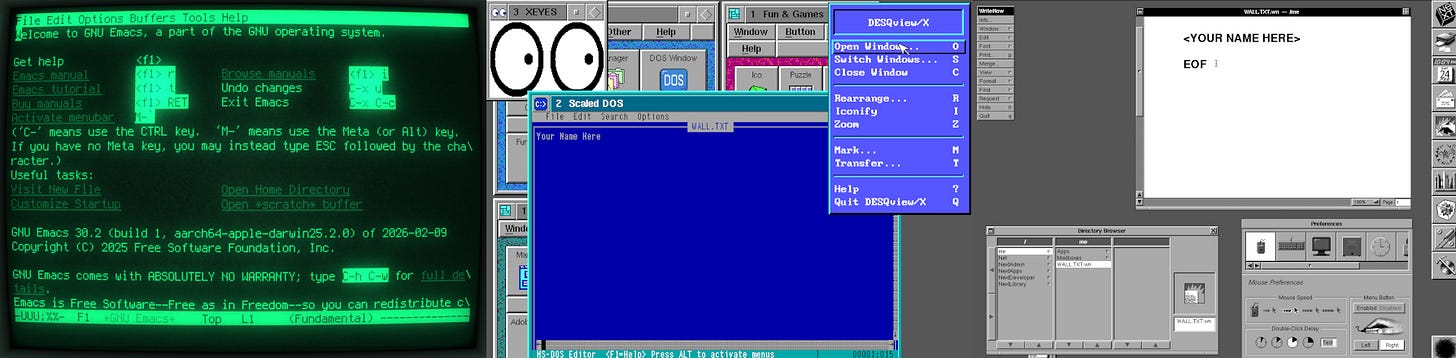
Which means there are, as of this exact moment, 4 Walls with space available (see Lunduke.com for the full list of Walls). But these fill up wicked fast.
Emacs (only a few spots left)
Desqview/X (a little less than 2/3rd’s full)
NeXTStep (still plenty of space)
TRS-80 Model 100 (just launched)
Nice, right?
Worth noting: The “TRS-80 Model 100” has very limited screen resolution (240 x 64), which means only a small number of names can fit on that wall. If you want on it, I’d let me know right away.
Grab a discounted Lifetime Subscription (if you don’t already have one), then let me know (email “bryan at lunduke.com”) which Wall you’d like to see your name on.
Huge high five to everyone who has already added their name to a Wall. At the current rate, we’ll have over 20 retro computer themed walls, filled with all of your names, by the end of the month.
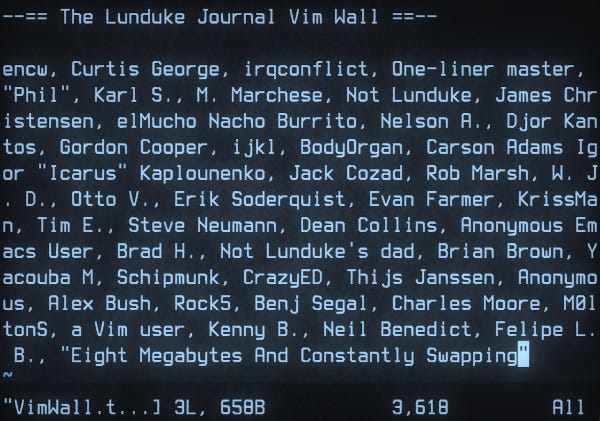
Now. How long will it take for Emacs to fill up (matching the same number of names as the Vim Wall)?
Well, right now the Emacs Wall is a hair over 2/3rds of the way full. So we’ll find out!
Welcome NeXTStep Wall!
With the closing of the “Vim” Wall (and the BeOS Wall only having the space for 1 name left), now seemed like a good time to add a new retro computer wall: The NeXTStep 1.0 Wall.
Right now, there are 4 Walls available to add your name to (*cough*massive discount*cough*).
As such, time that I normally would have spent writing up some thoughts on the Tech News of the Week (tm) was, instead, spent eating hamburgers, watching fireworks, and generally goofing off with my kids.
So allow me to briefly summarize my thoughts using as little effort as possible:
Rust is weird, Sony sucks, and America is awesome.
… Yup. That just about covers it.
I hope all of my fellow Americans had a truly splendid Independence Day.
Biggest Tech Stories - June 28 - July 4, 2026
Here are the major stories from the last week, with direct links to X and Substack.
See Lunduke.com for all other platforms (Rumble, RSS Audio Podcast, etc.).
Git Takes Another Step Towards Making Rust Mandatory (X, Substack)
74 Million User Accounts Exposed in Breaches During June (X, Substack)
BCacheFS Adding Rust Dependency Even Though “Rust doesn’t have a stable ABI” (X, Substack)
There are some options. For both subscribing and donating. They're all on this page.
Bonus: At the bottom of this page you will find the invite link to the super-secret Lunduke Journal Discord Chat Server. This is only available for full subscribers, which makes it a nice place to hang out. No riff-raff.
Only for Supporters
To read the rest of this article and access other paid content, you must be a supporter